import pandas as pd
df = pd.read_csv("filename") # CSV laden
df.head() # erste 5 Zeilen
df.tail() # letzte 5 Zeilen
df.info() # Überblick über Struktur
df.describe() # Statistische Kennzahlen (nur numerisch)
df.shape # Zeilen und Spalten
df.columns # Spaltennamen9 Pandas – die Standardbibliothek für Datenanalyse in Python

Pandas ist eine der zentralen Python-Bibliotheken für Datenanalyse und Datenaufbereitung. Sie baut auf NumPy (eine Bibliothek für effiziente numerische Berechnungen) auf und ergänzt dessen numerische Funktionen um eine leistungsfähige Tabellenstruktur, den sogenannten DataFrame.
Gerade in der Fahrzeugtechnik – wie auch allgemein in der Data Science – bietet Pandas entscheidende Vorteile:
Direkter Datenimport: CSV-, Excel- oder auch Datenbankformate können ohne Umwege eingelesen werden.
Effiziente Verarbeitung: Filterungen, Gruppierungen, statistische Auswertungen und Transformationen lassen sich mit wenigen Befehlen umsetzen.
Datenqualität sichern: Fehlende oder fehlerhafte Werte (NaN) können systematisch erkannt und behandelt werden.
Nahtlose Integration: Pandas arbeitet eng mit anderen Python-Bibliotheken zusammen – etwa für Visualisierung (Matplotlib, Seaborn) oder für Machine Learning (scikit-learn).
9.1 Daten einlesen und Überblick
9.2 Daten auswählen
Spalten auswählen
df["make"] # eine Spalte als Series
df[["make"]] # eine Spalte als DataFrame
df[["make", "year"]] # mehrere Spalten (DataFrame)Zeilen auswählen
df.iloc[0] # Integer location (erste Zeile im Datensatz, unabhängig vom Index)
df.iloc[[0, 2]] # mehrere Zeilen: 1. und 3.
df.loc[0] # Label location (Zeile mit Index 0)
df.loc[[0, 5]] # Zeilen mit Index 0 und 5Kombination aus Zeilen und Spalten
df.loc[0, "make"] # Wert aus Zeile mit Index 0 und Spalte "make"
df.iloc[0, 2] # Wert aus 1. Zeile und 3. Spalte
df.loc[[1, 3], ["make", "year"]] # Zeilen 1 und 3, Spalten "make" & "year"
df.iloc[[0, 2], [0, 3]] # Zeilen 1 und 3, Spalten 1 und 4 (Positionsbasiert)Slicing
df.iloc[0:5] # erste 5 Zeilen
df.loc[10:15, "make":"year"] # Zeilen 10–15 und Spalten von "make" bis "year"9.3 Operationen
Spaltenmanagement
df.rename(columns={"comb08": "consumption"}, inplace=True) # Spalte umbenennen
df["co2_per_mile"] = df["co2"] / df["comb08"] # neue Spalte berechnen
df.drop(columns=["old_column"], inplace=True) # Spalte entfernen
df["make_upper"] = df["make"].apply(lambda x: x.upper()) # Funktion auf Spalte ausführen
# und in neuer Spalte speichernGruppierungen & Aggregationen
df.groupby("make")["comb08"].median() # mittlerer Verbrauch pro Hersteller
df.groupby(["make", "year"])["co2"].mean() # Verbrauch pro Hersteller und JahrDaten filtern
df[df["year"] > 2015] # Fahrzeuge nach 2015
df[df["year"].gt(2015)] # Alternative Schreibweise (gt, ge, eq, le, lt)
df[df["fuelType"] == "Electricity"] # nur E-AutosSortieren
df.sort_values("year") # aufsteigend
df.sort_values("year", ascending=False) # absteigend
df.sort_values(["make", "year"]) # nach mehreren Spalten
df.sort_index() # nach Index sortierenEindeutige Werte und Zählen
df["make"].unique() # alle Hersteller
df["make"].nunique() # Anzahl unterschiedlicher Hersteller
df["make"].value_counts() # Hersteller zählenFehlende Werte
df.isnull().sum() # fehlende Werte zählen
df.dropna() # Zeilen mit NaN entfernen
df.fillna(0) # NaN durch 0 ersetzen9.4 Export
df.to_csv("vehicles_clean.csv", index=False) # zurückschreiben - ohne Indexspalte9.5 Datenvisualisierung am Beispiel von Palmers Pinguinen
Der Datensatz

Der Palmer Penguins-Datensatz wurde von der Palmer Station Long-Term Ecological Research (LTER) Initiative in der Antarktis erhoben. Er enthält Beobachtungen zu drei Pinguinarten (Adelie, Chinstrap und Gentoo) von den Inseln in der Palmer-Archipel-Region.
Erfasst sind biologische Merkmale wie Körpermasse, Flossenlänge, Schnabellänge und Schnabeltiefe, zusammen mit Geschlecht und Fundort. Der Datensatz dient häufig dazu, statistische Methoden, Datenvisualisierung und maschinelles Lernen zu demonstrieren, da er anschauliche und klar trennbare Kategorien bietet.
Barplot
Ein Barplot (Balkendiagramm) ist ein einfaches, aber sehr nützliches Werkzeug der Datenvisualisierung. Er stellt auf einer Achse Kategorien dar (z. B. Pinguinarten) und veranschaulicht ihre Häufigkeiten oder Werte durch die Länge der Balken. Besonders gut eignet sich ein Barplot für diskrete Variablen oder gruppierte Daten, etwa die Anzahl von Tieren pro Art, den Umsatz verschiedener Produkte oder Umfrageergebnisse.
Code
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# CSV-Datei einlesen
df = pd.read_csv("data/penguins.csv", low_memory=False).dropna()
ax = sns.countplot(data=df, x="species")
ax.set_xlabel("Pinguinart")
ax.set_ylabel("Anzahl")
ax.set_title("Verteilung der Pinguinarten")
ax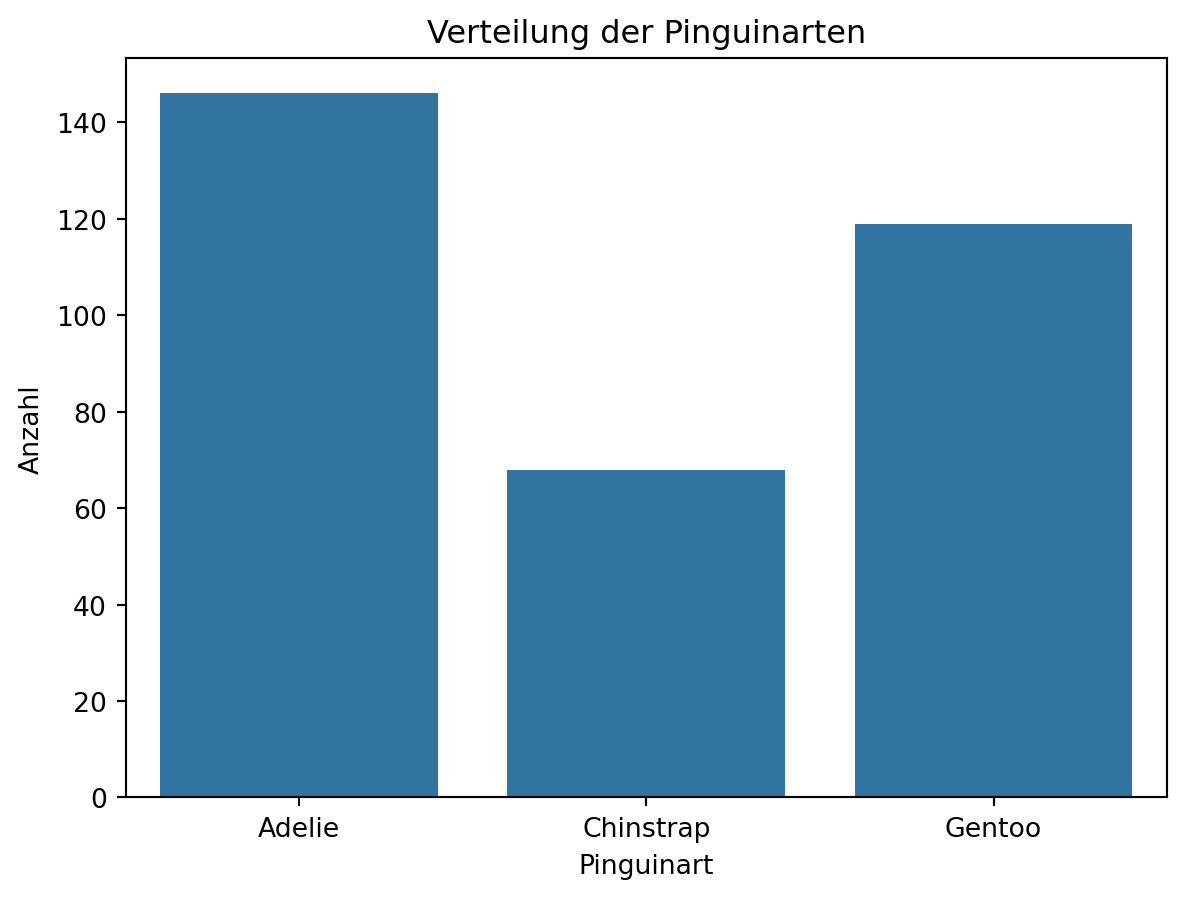
Histogramm
Ein Histogramm stellt die Verteilung einer numerischen Variable dar, indem die Werte in Klassen (Bins) eingeteilt und deren Häufigkeiten als Balken angezeigt werden.
Code
ax = sns.histplot(
data=df.query("species == 'Gentoo'"),
x="body_mass_g",
bins=20
)
ax.set_title("Verteilung der Körpermasse bei Gentoo-Pinguinen")
ax.set_xlabel("Körpermasse (g)")
ax.set_ylabel("Häufigkeit")
ax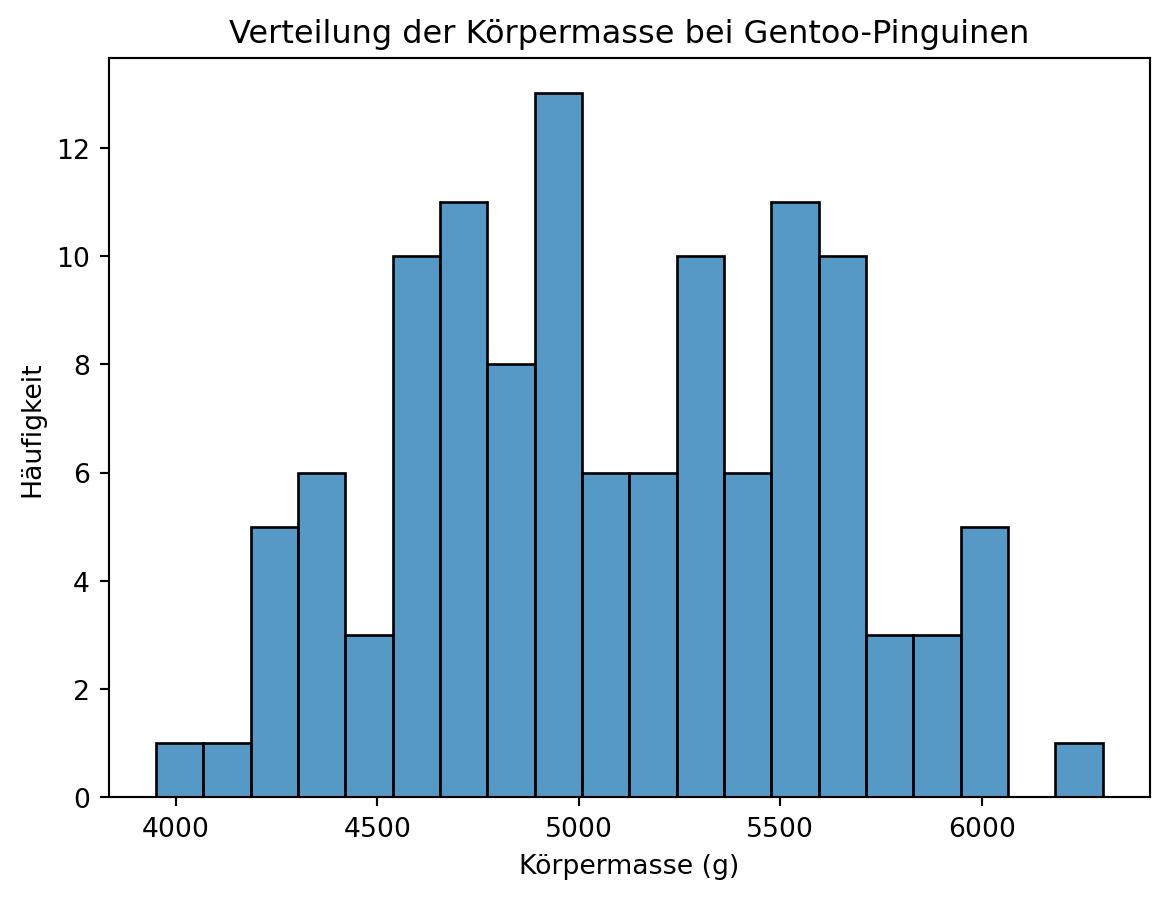
Boxplot
Ein Boxplot ist eine Darstellungsform, die die Verteilung von Daten zusammenfasst. Er zeigt den Median sowie obere und untere Quartile und macht Ausreißer sichtbar. Dadurch lassen sich Streuung und Unterschiede zwischen Gruppen gut vergleichen.
Code
# Boxplot: Körpermasse nach Art
ax = sns.boxplot(data=df, x="species", y="body_mass_g")
ax.set_xlabel("Pinguinart")
ax.set_ylabel("Körpermasse (g)")
ax.set_title("Boxplot der Körpermasse nach Art")
ax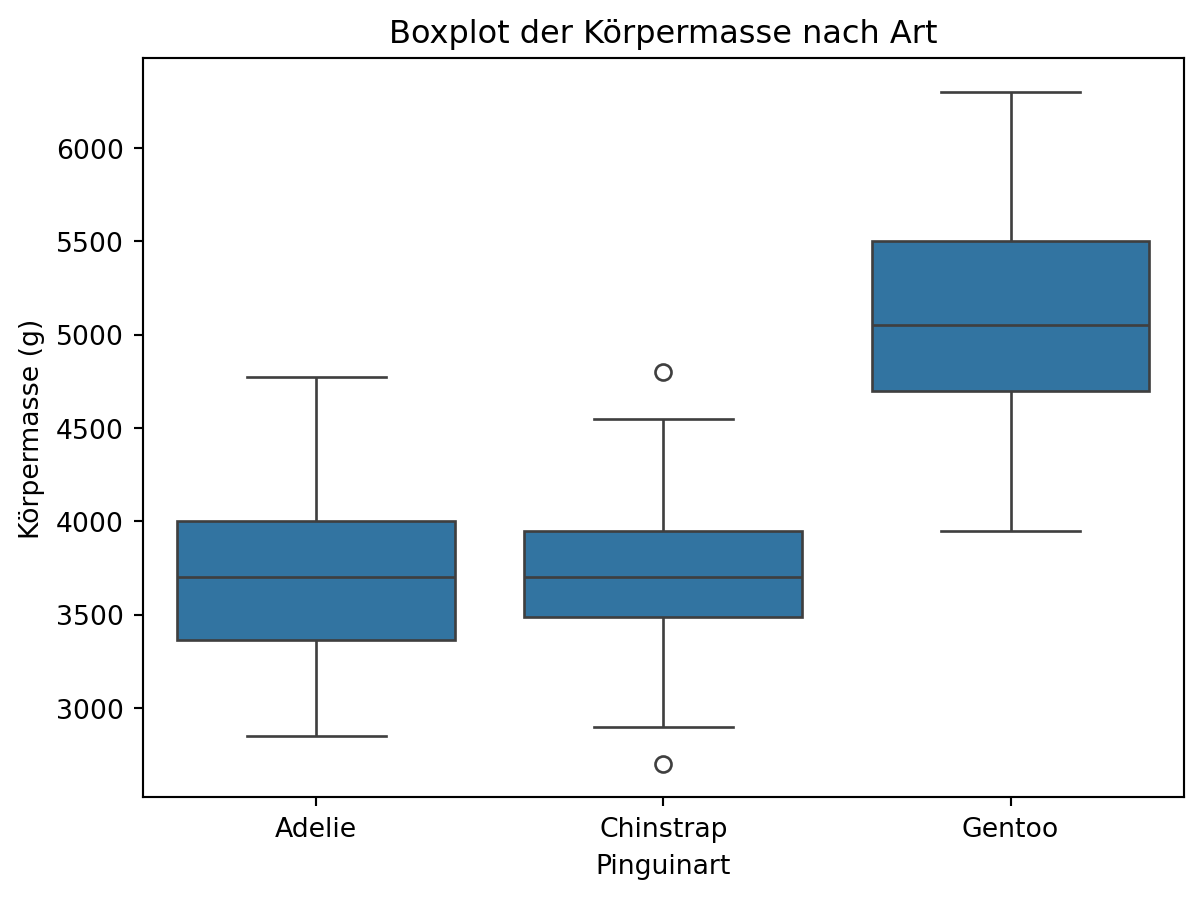
Scatterplot
Ein Scatterplot (Streudiagramm) zeigt Datenpunkte als Koordinaten in einem zweidimensionalen Raum. Er ist besonders nützlich, um den Zusammenhang zwischen zwei Variablen zu erkennen, Trends sichtbar zu machen und mögliche Cluster oder Ausreißer zu entdecken.
Code
ax = sns.scatterplot(
data=df,
x="bill_length_mm",
y="bill_depth_mm",
hue="species"
)
ax.set_xlabel("Schnabellänge (mm)")
ax.set_ylabel("Schnabeltiefe (mm)")
ax.set_title("Schnabellänge vs. Schnabeltiefe")
ax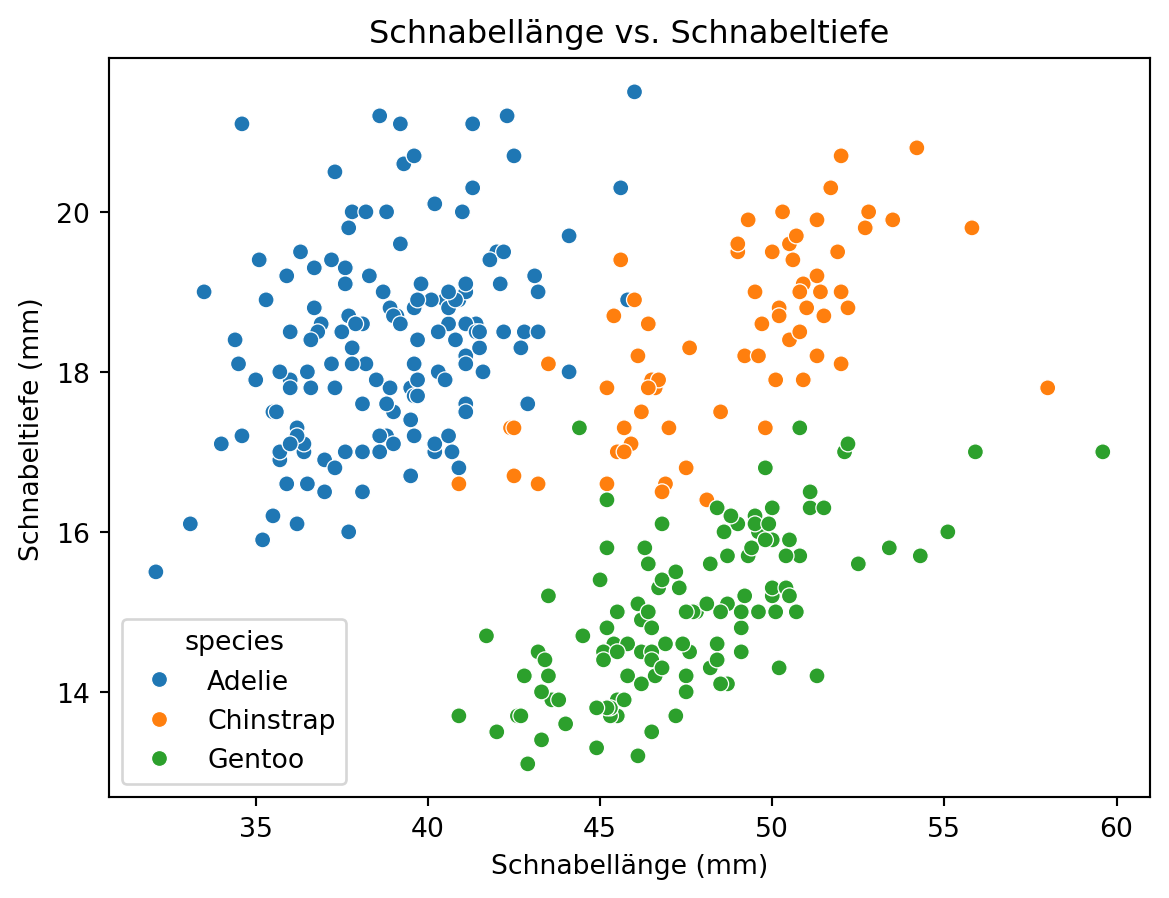
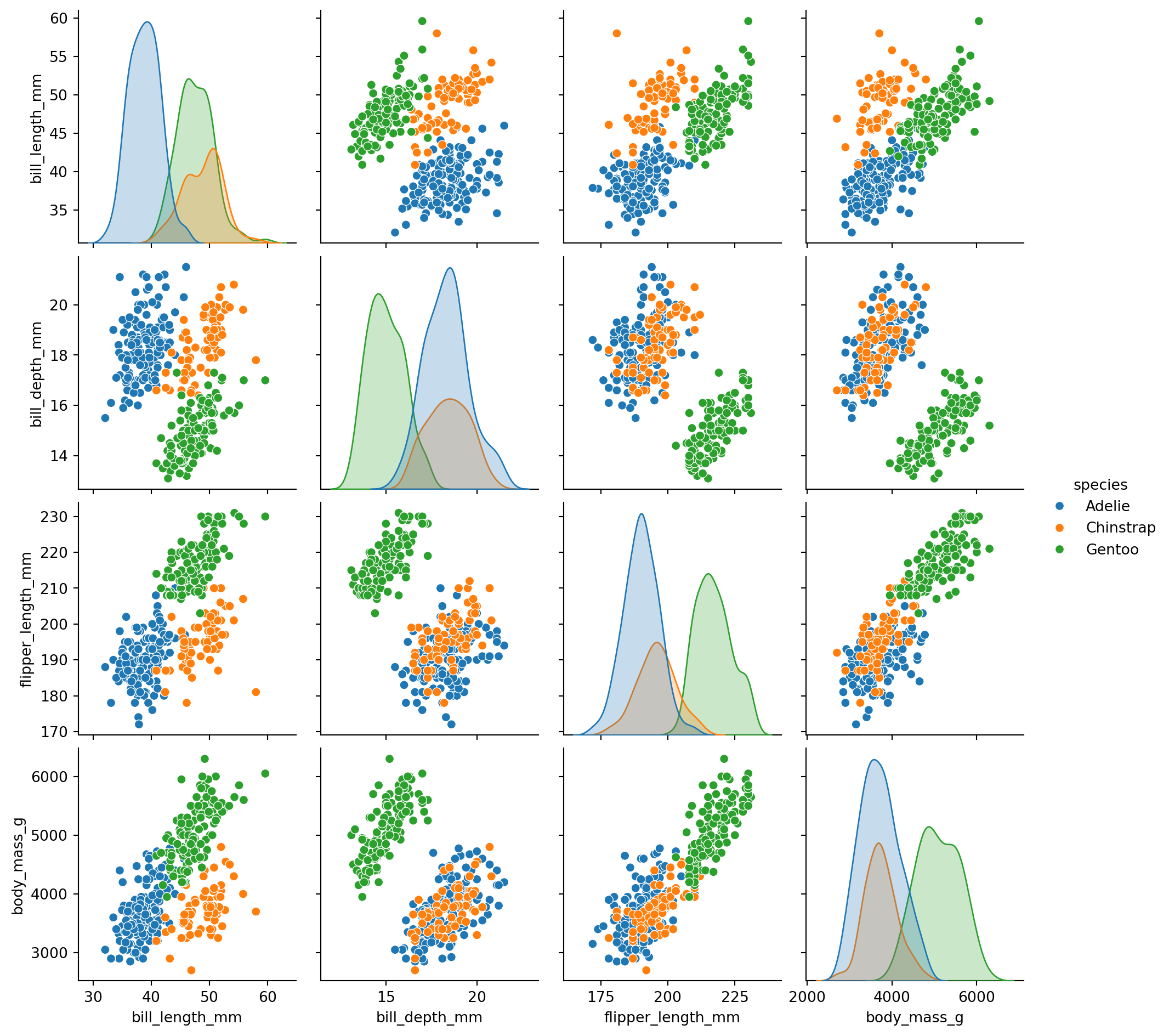
Pairplot
Eine Streudiagrammmatrix (Pairplot) zeigt gleichzeitig die Beziehungen zwischen mehreren numerischen Variablen. Auf den Achsenpaaren stehen Streudiagramme, auf der Diagonalen die Verteilungen. So lassen sich Zusammenhänge und Unterschiede zwischen Gruppen übersichtlich vergleichen.
Code
sns.pairplot(df, hue="species")