Neuronale Netzwerke, ein zentraler Bestandteil der Künstlichen Intelligenz, basieren auf einer vereinfachten Nachbildung biologischer Neuronen. In diesem Kapitel betrachten wir zunächst die Funktionsweise eines biologischen Neurons und leiten daraus ein einfaches künstliches Neuron ab.
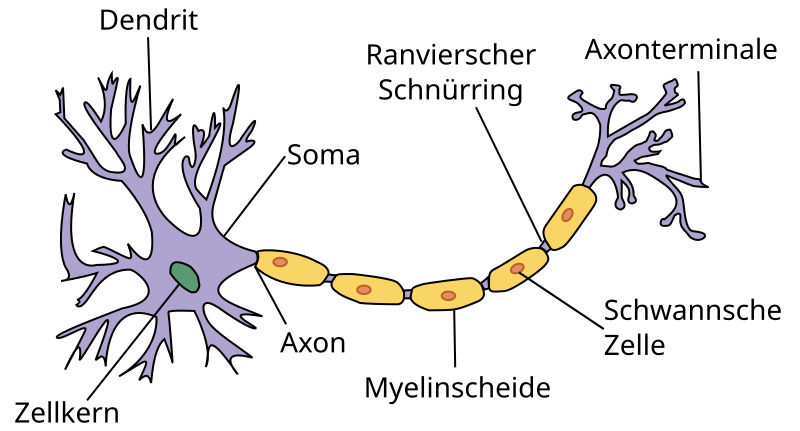
10.2 Das biologische Neuron
Ein biologisches Neuron besteht aus:
Dendriten: Eingangssignale von anderen Neuronen
Soma (Zellkörper): Verarbeitung der Signale
Axon: Weiterleitung des Ausgangssignals
Synapsen: Verbindung zu anderen Neuronen
Diese Struktur inspirierte die Entwicklung künstlicher Neuronen in der Informatik.
10.3 Das künstliche Neuron (Perzeptron)
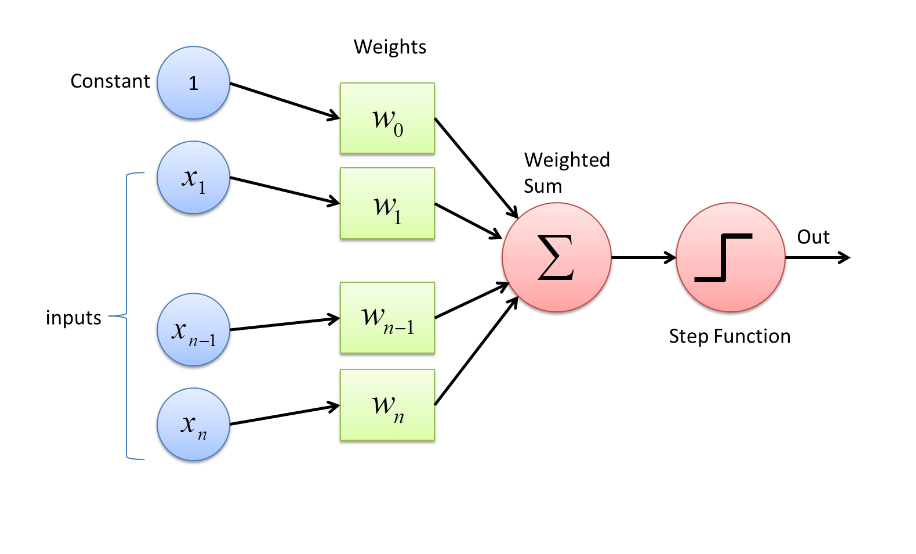
Ein einfaches künstliches Neuron berechnet eine gewichtete Summe seiner Eingänge und gibt ein Signal aus, wenn ein bestimmter Schwellwert überschritten wird.
10.3.1 Mathematische Definition
Ein Perzeptron mit \(n\) Eingängen berechnet:
\[
y = f\left( \sum_{i=1}^{n} w_i x_i + b \right)
\tag{10.1}\]
Symbol
Bedeutung
\(x_i\)
Eingabewerte
\(w_i\)
Gewichtungen
\(b\)
Bias (Schwellwert)
\(f\)
Aktivierungsfunktion (z.B. Heaviside-Funktion)
Ein künstliches Neuron erhält mehrere Eingabewerte \(x_i\). Diese können ganz unterschiedliche Bedeutungen haben – zum Beispiel Messwerte, Merkmale eines Datensatzes oder Signale anderer Neuronen. Jedem dieser Eingabewerte ist ein Gewicht \(w_i\) zugeordnet. Es bestimmt, wie stark der entsprechende Eingang das Neuron beeinflusst: Ein großes Gewicht verstärkt den Beitrag eines Eingabewerts, ein kleines oder negatives Gewicht schwächt ihn ab.
Zusätzlich besitzt das Neuron einen Bias \(b\). Er verschiebt den Entscheidungsbereich des Neurons und legt fest, wie leicht oder schwer es „aktiv“ wird. Man kann ihn sich wie einen anpassbaren Schwellwert vorstellen.
Alle diese Komponenten – Eingabewerte, Gewichte und Bias – werden zu einer einzigen Zahl kombiniert. Erst danach kommt die Aktivierungsfunktion \(f\) ins Spiel. Sie entscheidet, ob das Neuron ein Signal weitergibt oder nicht. In der einfachsten Form, der Heaviside-Funktion, geschieht dies durch einen klaren Schwellwert: Wird dieser überschritten, lautet die Ausgabe 1, ansonsten 0.
Auf diese Weise bildet ein künstliches Neuron eine stark vereinfachte Version seines biologischen Vorbilds ab: Es sammelt Signale, verarbeitet sie und entscheidet dann, ob es „feuert“.
10.3.2 Der Bias als zusätzlicher Eingang
In vielen Darstellungen wird der Bias \(b\) nicht separat behandelt, sondern als ein weiterer Eingang in die Summe aufgenommen. Dazu ergänzt man einfach einen künstlichen Eingabewert, der immer den festen Wert \(1\) hat. Der Bias wird dann zum zugehörigen Gewicht dieses zusätzlichen Eingangs.
Mathematisch bedeutet das:
Man definiert einen neuen Eingang \(x_0 = 1\).
Der Bias \(b\) wird zum Gewicht \(w_0\) dieses Eingangs.
Einheitliche Formulierung:
Ein Neuron besteht nun nur noch aus Eingängen und Gewichten – der Bias wird mathematisch genauso behandelt wie die anderen Gewichte.
Einfachere Darstellung in Vektoren und Matrizen:
In größeren Netzwerken lässt sich alles in kompakter Matrixform schreiben, ohne Sonderfall für den Bias.
10.3.3 Beispiel (Python-Code):
Code
class Perceptron:def__init__(self, weights, bias):self.weights = weightsself.bias = biasdef activate(self, z):"""Heaviside-Aktivierung."""if z >=0:return1else:return0def compute(self, inputs):"""Berechnet die Ausgabe des Perceptrons.""" total =0# gewichtete Summe berechnenfor i inrange(len(inputs)): total = total + inputs[i] *self.weights[i]# Bias hinzufügen total = total +self.biasreturnself.activate(total)# Beispielnutzungp = Perceptron(weights=[0.9, 1.2], bias=-0.1)inputs = [0.5, -0.6]output = p.compute(inputs)print("Output:", output)
10.4 Die Aktivierungsfunktion
Die gewichtete Summe der Eingaben liefert zunächst nur einen einzelnen Zahlenwert. Damit allein kann ein Neuron jedoch noch keine sinnvolle Entscheidung treffen. Hier kommt die Aktivierungsfunktion ins Spiel: Sie legt fest, wie das Neuron auf diese Summe reagiert und welche Ausgabe es erzeugt.
10.4.1 Was macht eine Aktivierungsfunktion?
Eine Aktivierungsfunktion \(f\) nimmt den Summenwert eines Neurons entgegen und berechnet daraus die endgültige Ausgabe. Sie bestimmt also:
ob das Neuron „aktiv“ wird,
wie stark es auf die Eingaben reagiert,
und wie empfindlich es gegenüber kleinen Änderungen der Eingaben ist.
Ohne Aktivierungsfunktion wäre ein Neuron lediglich eine lineare Kombination seiner Eingaben – und könnte daher nur sehr einfache Probleme lösen. Erst durch die Aktivierungsfunktion entsteht eine Nichtlinearität, die das Zusammenspiel vieler Neuronen leistungsfähig macht.
10.4.2 Wichtige Eigenschaften von Aktivierungsfunktionen
Je nach Anwendung können unterschiedliche Aktivierungsfunktionen sinnvoll sein. Viele haben jedoch einige gemeinsame Eigenschaften:
Begrenzte Ausgabewerte: Die Ausgabe liegt oft in einem festen Bereich (z. B. zwischen 0 und 1).
Nichtlinearität: Nur so können mehrere Neuronen gemeinsam komplexe Aufgaben lösen.
Differenzierbarkeit: Für das Trainieren mittels Gradientenverfahren ist eine glatte Funktion hilfreich.
Monotonie: Eine Funktion, die bei größeren Eingabewerten auch größere Ausgaben erzeugt, verhält sich intuitiv.
10.4.3 Beispiele für Aktivierungsfunktionen
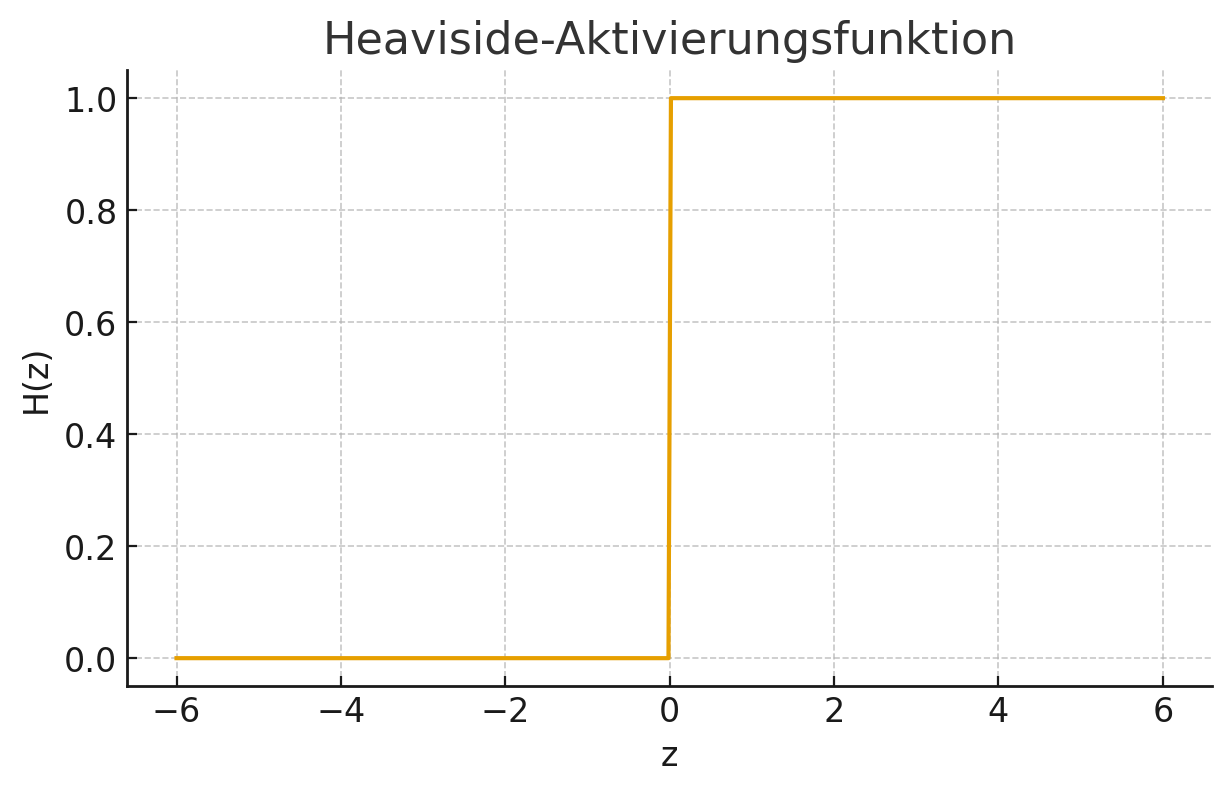
10.4.3.1 Heaviside-Funktion (Schwellwertfunktion)
Die einfachste Aktivierungsfunktion ist die Heaviside-Funktion. Sie entscheidet anhand eines festen Schwellwerts, ob das Neuron aktiv wird:
\[
H(z) =
\begin{cases}
1, & z \ge 0 \\
0, & z < 0
\end{cases}
\]
Sie bildet das Verhalten eines klassischen Perzeptrons nach: Das Neuron gibt entweder ein Signal weiter oder bleibt inaktiv.
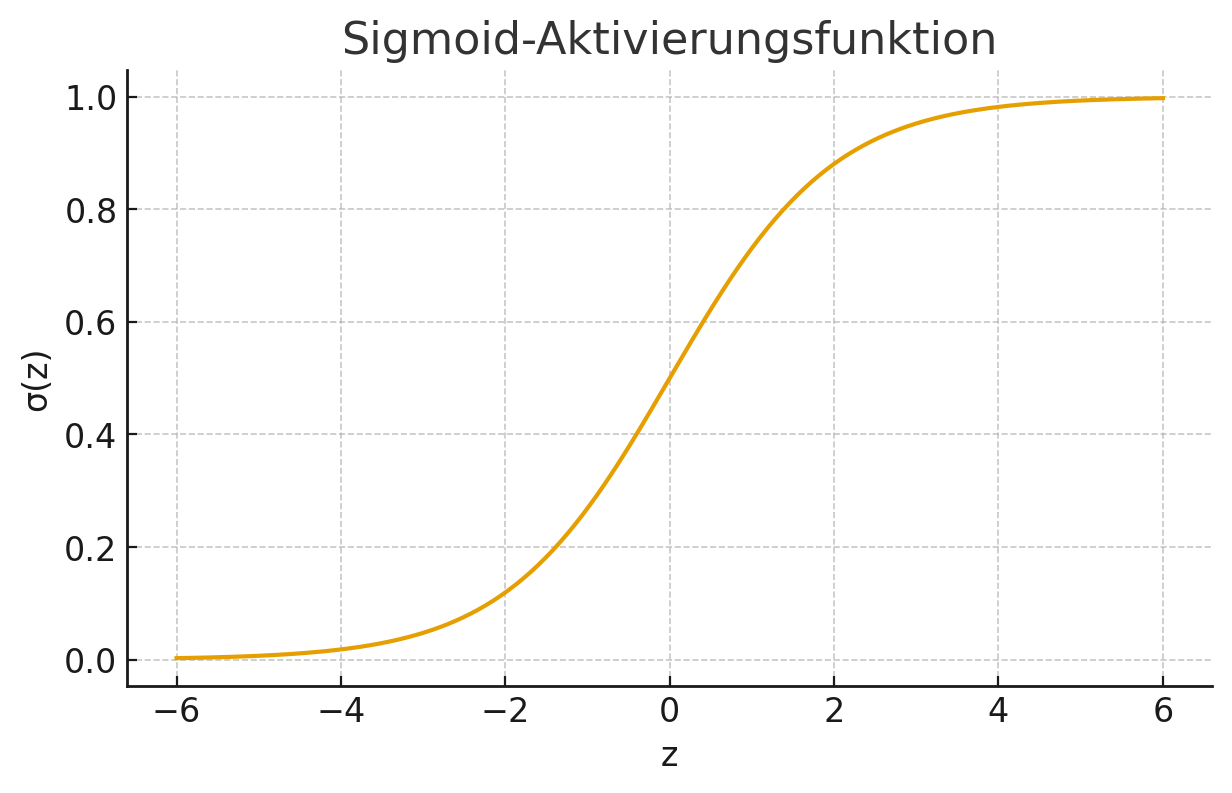
10.4.3.2 Sigmoid-Funktion
Eine etwas „weichere“ Variante ist die Sigmoid-Funktion:
\[
\sigma(z) = \frac{1}{1 + e^{-z}}
\]
Im Gegensatz zur Heaviside-Funktion springt sie nicht abrupt von 0 auf 1. Stattdessen steigt sie gleichmäßig an und erzeugt damit eine glatte und differenzierbare Übergangszone. Die Ausgabe liegt immer zwischen 0 und 1 – ähnlich wie bei einer Wahrscheinlichkeitsangabe.
10.5 Grenzen eines einzelnen Neurons
Ein einzelnes künstliches Neuron kann nur sehr einfache Entscheidungsaufgaben lösen.
Mathematisch betrachtet teilt es den Eingaberaum durch eine einzige Gerade (oder Hyperebene) in zwei Bereiche auf. Alle Eingaben auf der einen Seite führen zur Ausgabe \(1\), alle auf der anderen zur Ausgabe \(0\).
Damit lassen sich nur linear trennbare Probleme lösen.
Ein klassisches Beispiel dafür ist die logische UND- oder ODER-Funktion.
Es gibt jedoch viele Aufgaben, die sich nicht mit einer einzigen Geraden trennen lassen – zum Beispiel die XOR-Funktion. Hier stößt ein einzelnes Perzeptron an eine grundlegende Grenze. Um solche Probleme bearbeiten zu können, benötigt man mehrere Neuronen, die gemeinsam arbeiten.
10.5.1 Anekdote: Das XOR-Problem und der erste Dämpfer der KI-Forschung
In den 1950er-Jahren entwickelte Frank Rosenblatt das Perzeptron und weckte damit große Hoffnungen. Zeitungen berichteten begeistert, seine lernfähige Maschine könne eines Tages „denken wie ein Gehirn“. Rosenblatt selbst war überzeugt, dass neuronale Modelle grundsätzlich in der Lage seien, sehr komplexe Aufgaben zu erlernen.
Doch 1969 folgte die Ernüchterung: Marvin Minsky und Seymour Papert veröffentlichten ihr Buch Perceptrons und zeigten darin mathematisch, dass ein einzelnes Perzeptron grundlegende Probleme wie die XOR-Funktion nicht lösen kann, weil sie nicht linear trennbar ist.
Diese Erkenntnis traf die junge KI-Forschung hart. Viele sahen darin eine grundsätzliche Grenze künstlicher Neuronen, und die Finanzierung brach ein – man spricht heute vom ersten „AI Winter“. Tragischerweise konnte Rosenblatt seine Vision nicht mehr verteidigen, da er 1971 bei einem Unfall ums Leben kam.
Ironischerweise stellte sich später heraus, dass Minsky und Papert nur die Grenzen einer einzigen Schicht beschrieben hatten. Mehrschichtige Netzwerke können XOR sehr wohl lösen. Doch zur Zeit Rosenblatts wusste noch niemand, wie man solche Netzwerke effizient trainieren kann.
Erst in den 1980er-Jahren – mit der Wiederentdeckung und Popularisierung des Backpropagation-Algorithmus – gelang der Durchbruch, und neuronale Netze feierten ihr Comeback.
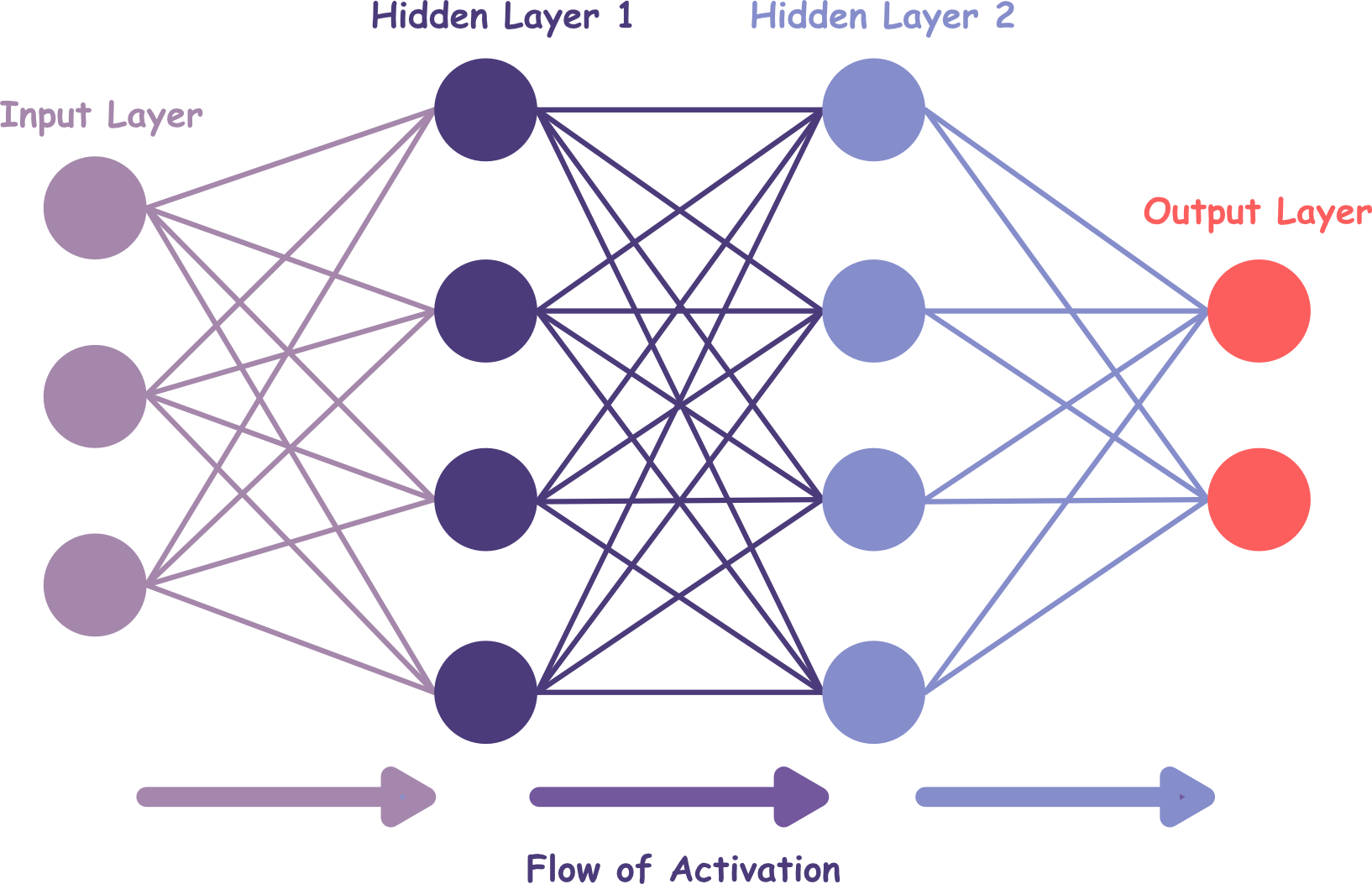
10.6 Von einzelnen Neuronen zu Netzwerken
Wenn man mehrere künstliche Neuronen miteinander verbindet, entsteht ein Neuronales Netzwerk. Die Ausgaben einiger Neuronen dienen dabei als Eingaben für andere. Auf diese Weise können mehrere einfache Entscheidungen kombiniert werden, um komplexere Zusammenhänge zu erkennen.
Typische Struktur:
Eingabeschicht: nimmt Rohdaten auf
Verborgene Schichten (Hidden Layers): verarbeiten die Informationen
Ausgabeschicht: liefert das Ergebnis
Jede zusätzliche Schicht erlaubt dem Netzwerk, neue Muster zu erkennen, die ein einzelnes Neuron nicht erfassen könnte.
Aufbau eines Fully Connected Neural Network
10.6.1 Ein theoretisches Fundament: Das Universal Approximation Theorem
Mehrschichtige neuronale Netzwerke besitzen nicht nur mehr Flexibilität als ein einzelnes Perzeptron – sie verfügen auch über eine bemerkenswerte mathematische Eigenschaft. Diese wird als Universal Approximation Theorem bezeichnet.
In seiner gebräuchlichsten Form besagt es im Kern:
Ein neuronales Netzwerk mit mindestens einer versteckten Schicht und einer geeigneten nichtlinearen Aktivierungsfunktion kann jede stetige Funktion auf einem begrenzten Bereich beliebig genau approximieren – sofern die Schicht groß genug gewählt wird.
Das bedeutet, dass Neuronale Netzwerke dieser Bauart prinzipiell in der Lage sind, jede stetige Abbildung nachzuformen. Für jede gewünschte Funktion existiert ein Netzwerk mit passenden Gewichten, das sie mit beliebiger Genauigkeit annähern kann.
Dabei bedeutet das nicht, dass ein einziges fixes Netzwerk „alles kann“.
Vielmehr ist die Architektur an sich so ausdrucksstark, dass sie – bei geeigneter Wahl der Gewichte und genügend Neuronen – praktisch jeden funktionalen Zusammenhang repräsentieren kann.
Die entscheidende Rolle spielt dabei die Nichtlinearität:
Ohne Aktivierungsfunktionen könnten mehrere Schichten nur eine verschachtelte lineare Abbildung darstellen. Erst durch nichtlineare Aktivierungen können Netzwerke ihre Entscheidungsgrenzen „verbiegen“ und so hochkomplexe Formen abbilden.
Das Universal Approximation Theorem sagt nichts über die Effizienz des Trainings oder die nötige Netzgröße aus. Es liefert jedoch ein fundamentales Ergebnis:
Mehrschichtige neuronale Netzwerke sind theoretisch universelle Funktionsapproximatoren – und bilden damit die Grundlage für viele moderne KI-Verfahren.
10.7 Wie neuronale Netzwerke lernen – ein Überblick
Damit ein neuronales Netzwerk nützliche Entscheidungen trifft, müssen die Gewichte und der Bias jedes Neurons geeignet gewählt werden. Anfangs sind sie meist zufällig gesetzt.
Beim Lernen versucht das Netzwerk, seine Gewichte so zu verändern, dass die Fehler bei der Ausgabe kleiner werden.
Die Grundidee dabei ist:
Netzwerk produziert eine Ausgabe
Vergleich mit der gewünschten Ausgabe
Aus dem Fehler wird gelernt ⟶ die werden Gewichte angepasst
Dieser Prozess wird viele Male wiederholt, bis das Netzwerk die Aufgabe gut beherrscht. Die mathematischen Details dazu – insbesondere der Backpropagation-Algorithmus – werden in einem späteren Kapitel ausführlich behandelt.
10.7.1 Beispiel (Python-Code):
Code
class Neuron:def__init__(self, weights, bias):self.weights = weightsself.bias = biasdef activate(self, z):if z >=0:return1else:return0def compute(self, inputs): total =0for i inrange(len(inputs)): total = total + inputs[i] *self.weights[i] total = total +self.biasreturnself.activate(total)class Layer:def__init__(self, neurons):self.neurons = neuronsdef compute(self, inputs): outputs = []for neuron inself.neurons: y = neuron.compute(inputs) outputs.append(y)return outputsclass NeuralNetwork:def__init__(self, layers):self.layers = layersdef compute(self, inputs): current = inputsfor layer inself.layers: current = layer.compute(current)return current